Create a new Tool or IP description!
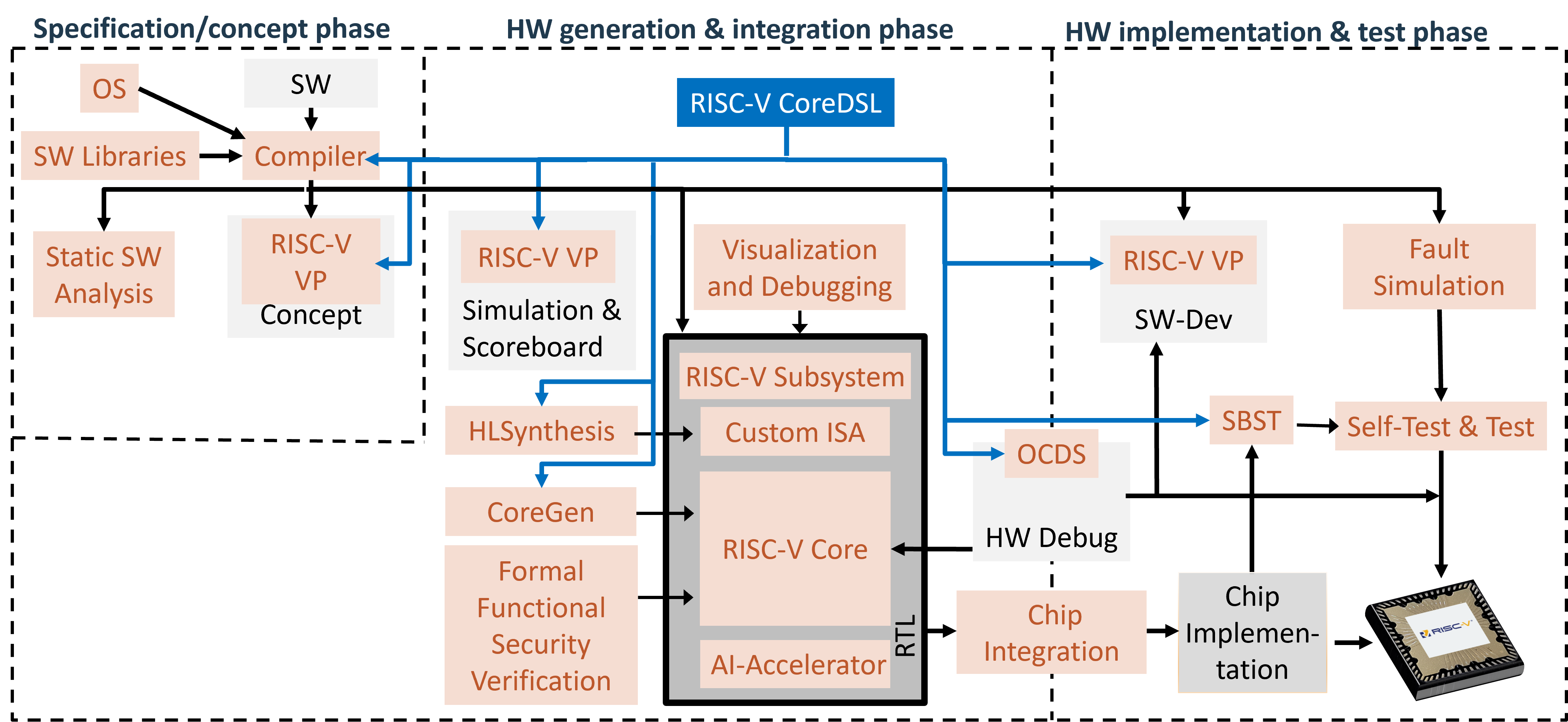
The Scale4Edge eco system offers IP, tools and methods in 19 categories.
| Body | ISA Compliance | Contact | |
|---|---|---|---|
| Longnail High-Level Hardware Synthesis of Custom RISC-V Instructions | The Longnail High-Level Synthesis system translates abstract descriptions of the semantics of custom instructions formulated in CoreDSL 2.0 into actual hardware-blocks in RTL. CoreDSL 2.0 is styled after the C programming language, with which many embedded applications developers will be familiar. Longnail automatically performs the many steps that would be required to translate such an algorithmic into efficient hardware, including optimized scheduling, resource sharing, memory block selection etc. It targets the SCAIE-V interface, also created in Scale4Edge, and is thus portable to all processors on which SCAIE-V is supported. This currently ranges from small MCU-class cores up to Linux-capable application class cores such as the OpenHWGroup's CVA6. The resulting hardware block is exported as RTL in SystemVerilog and can then be passed on to traditional ASIC design tools for further processing. Longnail will be licensed to MINRES Technologies GmbH for commercial use. Academic research-only users should also contact the company for specialized licenses. |
X: Custom ISA Extensions, X = ISA Extension (automated) | TU Darmstadt |
| SCAIE-V Scalable ISA Extension Interface for RISC-V Cores | The SCAIE-V interface is a portable interface for extending RISC-V core with custom instructions. It applies to both pipelined and non-pipelined core. The custom instructions supported do not just cover Register-type instructions, but also extend to custom control flow (jumps, branches) and custom memory operations. SCAIE-V supports executing complex custom instructions more efficiently by decoupling their execution from the base processor, and automatically inserting the required hazard handling logic to guarantee their correct interoperation with regular RISC-V instructions. The technology has been demonstrated on a number of processors, reaching from non-commercial (e.g., VexRiscv, CVA5, CVA6, ...) to commercial cores (MINRES TGC family). SCAIE-V forms the target of the Longnail High-Level Synthesis system that can create the actual hardware for the custom instructions from abstract descriptions in the CoreDSL 2.0 language. |
AI/DSP-IP: Application-specific accelerators, AI/DSP-IP: CoreDSL 2.0, Code Size Reduction (like Zc) with ISAX macro instructions, Resource-optimised ISAX generation from CoreDSL, Smart Float, e.g. Bfloat16, ANT; IEEE 754, Smart Float, e.g. Bfloat8, ANT; IEEE 754, X: Custom ISA Extensions, X = ISA Extension (automated), X = ISA Extension (manuell), X: Autoincrement Load+Store, X: Multiply-Accumulate, X: Zero Overhead Loop | TU Darmstadt |
| UPEC: Formal Security Verification | Figure: Speculative program execution can enable side channel Unique Program Execution Checking (UPEC) is a method for formally verifying the security of hardware at the RTL. UPEC checks whether confidential data in the system can be stolen by an attacker (user program) for any programs that can be executed on the hardware. UPEC detects all confidentiality violations that are made possible by so-called transient execution side channels of the microarchitecture. Spectre and Meltdown are well-known examples of this class of vulnerabilities. In addition, UPEC also uncovers all confidentiality vulnerabilities that can arise due to design errors (“HW bugs”), which easily occur when implementing protection mechanisms. In Phase 1 of the Scale4Edge project, the security analysis focuses primarily on cores ranging from smaller in-order cores to larger out-of-order processors. The focus is on transient execution side channels. In Phase 2, UPEC will be extended to entire SoCs. SoCs pose different security challenges than processor cores, including secure system integration, functional design flaws, and system integrity violations. |
Not Applicable | RPTU Kaiserslautern-Landau |
| Moonlight | Moonlight is a subsystem around a TGC core developed by MINRES. The Good Core (TGC) [1] is a highly flexible, scalable and expandable RISC-V processor core and the TGC variant to be used in the subsystem is configurable. Moonlight contains a configurable APB3 subsystem with a customizable number of different peripherals, e.g., GPIO, UART, Timer, SPI, I2S Receiver, DMA. It features an AMBA-compatible high-speed bus connecting a memory system, a CPU, and an APB bridge. As optional additions, application-specific components as well as bridges to other bus systems can be integrated. |
Not Applicable | MINRES |
| QTA - QEMU Timing Analyzer | The QEMU Timing Analyzer (QTA) is a QEMU plugin which extends QEMU for the time annotated execution of binary programs. QTA has been tested only for RISC-V and TriCore. As the implementation extends QEMU through TCG plugin API it should be compatible with any other ISA and all future QEMU versions . QTA comes with a frontend that can import output files from AbsInt aiT WCET analysis. |
Not Applicable | Paderborn University / Heinz Nixdorf Institut |
| muRISCV-NN | We introduce muRISCV-NN, an open-source compute library for embedded and microcontroller class systems. muRISCV-NN targets to provide an open-source, and vendor-agnostic compute library targeting all RISC-V-compliant platforms for supplying a HW/SW interface between industry-standard deep learning libraries and emerging ultra-low-power compute platforms. Forked from ARM’s CMSIS-NN library, muRISCV-NN provides optimized scalar kernels written in plain C as an efficient and highly portable baseline. Additionally, we provide hand-optimized vectorized kernels employing either the V or P extensions. muRISCV-NN is designed to be lightweight and modular, and is implemented as a static library that can be linked to the application software and accessed through a single header file. Furthermore, muRISCV-NN is bit-accurate to CMSIS-NN and can, thus, be used as a drop-in replacement with only minor changes to the compilation flow. This makes its use with higher-level frameworks completely transparent and enables a seamless transition from ARM-based systems to RISC-V. As a proof of concept, we provide full integration support with both TensorFlow Lite for Microcontrollers and microTVM. We demonstrate the effectiveness of muRISCV-NN on the MLPerf Tiny benchmark, observing up to a 9x speedup and 5x EDP reduction compared to the plain C-Version of CMSIS-NN across all four benchmarks. |
RISC-V for Low Power SoC, RV32I - Base Integer, 32-bit, RV64I - Base Integer, 64-bit, P - Packed-SIMD Instructions, V - Vector Operations | Technical University of Munich |
| Ecosystem Microcontroller | The Ecosystem microcontroller is a PULPissimo-based microcontroller featuring the following Scale4Edge ecosystem IPs:
Due to the high configurability of the individual components, the platform can be quickly and easily adapted to specific applications. A specialized ecosystem microcontroller was taped-out in 22nm FDSOI technology as a demonstrator for an audio event detection use-case provided by the project partner Bosch. |
AI/DSP-IP, RISC-V for Low Power SoC, RV32I - Base Integer, 32-bit, X: Custom ISA Extensions, X: Multiply-Accumulate, X: Zero Overhead Loop, C - Compressed Instructions, M - Multiplication / Division | University of Tübingen |
| SymEx-VP | SymEx-VP focuses explicitly on testing software for constrained embedded devices (e.g. as used in the Internet of Things). This software often interacts very closely with low-level hardware peripherals and in order to support these interactions, during simulation-based software testing, SymEx-VP supports SystemC peripheral models. SystemC is a C++ class library for modeling hardware peripherals. SystemC is often used to create executable models of an entire hardware platform, so-called Virtual Prototypes (VPs). Using these SystemC peripherals models, SymEx-VP allows injecting test inputs into the software simulation via the MMIO peripheral interface. Thereby allowing tests of embedded software with only minimal software modifications. SymEx-VP is implemented on top of the existing riscv-vp codebase and integrates this existing VP with the clover concolic testing library. |
Exception - Basic, Exception - 1 Level (Machine Level only) - for Compiler: Assembler only, Exception - Basic, Counter, RV32I - Base Integer, 32-bit, X = ISA Extension (manuell), A - Atomic Instructions, C - Compressed Instructions, M - Multiplication / Division, N - User-Level Interrupts, Zicsr - Control and Status Register (CSR) | Universität Bremen |
| MLonMCU | While there exist many ways to deploy machine learning models on microcontrollers, it is non-trivial to choose the optimal combination of frameworks and targets for a given application. Thus, automating the end-to-end benchmarking flow is of high relevance nowadays. MLonMCU allows performing complex benchmarks of edge ML workloads, frameworks and targets with minimal efforts |
Not Applicable | Technical University of Munich |
| UMA: Universal Modular Accelerator Interface | UMA (Universal Modular Accelerator Interface) is a unified infrastructure for easy integration of external hardware accelerators into the machine learning compiler framework TVM. UMA provides file structures, Python interface classes and a documented API and is available open-source in the latest releases of TVM. |
Not Applicable | Paul Palomero Bernardo |
| Fault Effect Simulation and Analysis for RISC-V (FEAR-V) | FEAR-V is a fast scalable simulation and analysis framework for RISC-V architectures based on QEMU. The generation, simulation, and analysis can be scaled by ISA configuration as well as n-bit permanent and transient faults. The fault injection covers GPR, CSR, instruction, and memory analysis. The framework comes with a SW library and a front-end for C source code program generation, which are compiled to RV32 target binaries of the specified ISA subset. Each SW binary is dynamically analyzed for its instruction, register, and memory execution coverage. After automatic mutant generation for fault simulation the different fault injected mutants are executed with exception, timeout, and signature violation error detection. A final optimization step with optional weights minimizes the set of SW programs with the same coverage. |
RV32I - Base Integer, 32-bit, RV32E - Base Integer (embedded), 32-bit, A - Atomic Instructions, B - Bit Manipulation, C - Compressed Instructions, D - Double-Precision Floating-Point, F - Single-Precision Floating-Point, G - Shorthand for IMAFD, M - Multiplication / Division, Zicsr - Control and Status Register (CSR), Zifencei - Instruction-Fetch Fence | Paderborn University / Heinz Nixdorf Institut |
| SpiNNedge DSP/AI Accelerator | The SpiNNedge accelerator is designed for ultra-low-power processing and classification of time series from sensors in real time. It combines DSP functions for data preprocessing and feature extraction (frequency transforms, windowing, filtering, logarithm) with classification based on recurrent neural networks (RNN). The RNN module exploits sparsity for significantly reduced storage and processing effort. The accelerator performs individual processing layers autonomously. Complex layers can be flexibly assembled from base operations via a global control module. The SpiNNedge accelerator is specifically optimized for audio processing tasks like keyword spotting, e.g. supporting MFCC feature extraction from raw audio data. A backend for machine learning frameworks like TensorFlow, including RISC-V code generation, quantization and data handling, allows for easy deployment of RNN models onto the accelerator. Due to the shared memory between RISC-V and SpiNNedge, mixed deployment schemes can be realized with virtually no overhead, making the architecture adaptable to new user requirements even after manufacturing. The SpiNNedge accelerator has been validated in two chips and demonstrated in audio (keyword spotting) and predictive maintenance use cases. |
Not Applicable | TU Dresden |
| HighRel Multiprozessor | The HighRel Multiprocessor is a Pulpissimo-based quad-core processing system that is specifically built to withstand the harsh environments as they occur in avionics or astronautics. Based on the required processing power as well as different health and environmental monitors, the system is able to autonomously configure itself to various states of fault tolerance (DMR, TMR or QMR) or performance (low power or high performance). The second and improved version, TETRISC v2, now features heterogeneously hardened cores, improved ResilliCell design, digital health monitors and improved performance. |
Not Applicable | IHP - Leibniz-Institut für innovative Mikroelektronik |
| CHIPS Verification Framework | The CHIPS Verification Framework is a collection of tools and libraries for (formal) hardware design verification. The framework encompasses two subprojects: CHIPS: Chisel Hardware Property Specification LanguageThe foundation of the CHIPS-VF is a domain-specific language (DSL) embedded in Scala that allows the specification of lightweight verification properties on different levels of abstraction using the assertion-based verification paradigm. Extended CIRCT Hardware CompilerCIRCT is a hardware compiler based on the LLVM/MLIR compiler framework. The CIRCT hardware compiler is extended to support high-level CHIPS assertions which are compiled into System Verilog Assertions (SVAs) during hardware design elaboration. |
Not Applicable | FZI Forschungszentrum Informatik |
| On Chip Debug Solution | Lauterbach implements debugging and trace support in alignment with Partner Infineon specific Hardware Solution. |
Not Applicable | Lauterbach Engineering GmbH |
| FreiTest | FreiTest (developed from PHAETON) is an ATPG (Automatic Test Pattern Generation) Framework based on SAT-Solving (Boolean Satisfiability Problem) and BMC (Bounded Model Checking). It generates Test Patterns and Software-Based Self-Tests (SBSTs) for synthesized circuits and is under active development. First results on achieved Fault Coverages have been published on the IEEE ETS2023 conference in Venice under the title "Constraint-Based Automatic SBST Generation for RISC-V Processor Families". |
E = 16 (instead of 32) CPU Register, RV32I - Base Integer, 32-bit, RV32E - Base Integer (embedded), 32-bit, RV64I - Base Integer, 64-bit, A - Atomic Instructions, B - Bit Manipulation, D - Double-Precision Floating-Point, F - Single-Precision Floating-Point, G - Shorthand for IMAFD, M - Multiplication / Division, P - Packed-SIMD Instructions, Zicsr - Control and Status Register (CSR), Zifencei - Instruction-Fetch Fence | Tobias Faller |
| tflite_micro_compiler | Generate tflite micro code which bypasses the interpreter (directly calls into kernels) Basically this code uses a fully set up tflite micro instance to dump the internal allocations and function calls assigned to the model, then dumps the tensor and node settings into a compilable file, eliminating the need for running the interpreter at each program start and for resolving the correct kernel at run time. An in depth explanation of the motivation and benefits is included in the matching RFC: https://docs.google.com/document/d/1wDqC50sjCaWyQxsSn_Y-XAGh8-ozIgm2HDzX_b9DIyo/edit?usp=sharing |
Not Applicable | Technical University of Munich |
| PikeOS Operating System and Hypervisor | PikeOS and PikeOS for MPU are each a real-time operating system and hypervisor for embedded systems. It provides partitioning to separate different applications or guest operating systems from each other. PikeOS is often combined with ELinOS, SYSGO's embedded Linux, which is then run in a partition under the PikeOS hypervisor. PikeOS is available for multiple architectures, and due to the Linux use case, it targets systems with an MMU. In the Scale4Edge project, SYSGO develops a RISC-V RV64I port of PikeOS. PikeOS MPU targets systems with no MMU, but an MPU for memory protection. In Scale4Edge, SYSGO develops a RISC-V RV32I port for PikeOS MPU, with support for optional hardware modules, like FPU support or instruction set extensions. For Phase 1, the target TRL is reached for RV64 with MMU. For Phase 2, SYSGO plans to reach the TRL for RV32 RISC-V architecture with MPU support. |
RV64I - Base Integer, 64-bit, A - Atomic Instructions, D - Double-Precision Floating-Point, F - Single-Precision Floating-Point, G - Shorthand for IMAFD, H - Hypervisor, M - Multiplication / Division, Zicsr - Control and Status Register (CSR), Zifencei - Instruction-Fetch Fence, User & 2 privileged modes, User (U-mode, lowest privileges), Supervisor (S-Mode), Machine (M-Mode, highest privileges) | SYSGO GmbH |
| Extensible Compiler (X-LLVM, Seal5) | The Extensible Compiler provides an LLVM-based toolchain to develop C/C++/Assembly programs for RISC-V. It is designed to easily accommodate custom extensions to the RISC-V ISA by supporting the Scale4Edge developed CoreDSL for describing ISA extensions. RISC-V extensions in the Scale4Edge project are described using a separate language called CoreDSL. An automated translation of these CoreDSL definitions into corresponding tool hain extensions, as far as possible, is therefore not only desirable for reasons of flexibility, but also almost inevitable for reasons of consistency. For this reason, the described hardware (processor core) and a virtual platform and a compiler with support of custom defined instructions can be generated from CoreDSL. We have successfully automated the modification of Clang/LLVM to support custom instructions throughout the whole software tool chain (compiler, linker debugger). Based on a CoreDSL description of the custom instructions, the extendible compiler tool chain (originally X-LLVM, now continued together with TUM as Seal5) implements a compiler generator to provide the defined custom instructions as assembler code or intrinsic function for explicit usage. If possible, custom instructions are also implicitly used by the compiler (e.g., MAC (Multiply Accumulate) or Zero Overhead Loop). If this were done based on a manual translation, there would be a potential for an incorrect or at least inconsistent translation at each individual step. By automating this process, these errors can be avoided. Another benefit of automation is the speed with which the different artifacts can be regenerated. For example, if a new CoreDSL description is created or an existing description is revised, the corresponding tool chains can be triggered directly to generate the different artifacts and thus be able to test the newly defined instructions directly and revise them further if necessary. |
RV32I - Base Integer, 32-bit, X: Custom ISA Extensions, X = ISA Extension (automated), X = ISA Extension (manuell), X: Multiply-Accumulate, X: Zero Overhead Loop, RV32E - Base Integer (embedded), 32-bit, RV64I - Base Integer, 64-bit, A - Atomic Instructions, B - Bit Manipulation, C - Compressed Instructions, D - Double-Precision Floating-Point, F - Single-Precision Floating-Point, M - Multiplication / Division, Zicsr - Control and Status Register (CSR) | Deutsches Zentrum für Luft- und Raumfahrt, Institut für Systems Engineering für zukünftige Mobilität |
| UltraTrail - Ultralow-Power AI Accelerator for Edge Devices | UltraTrail is a configurable hardware accelerator for real-time inference of temporal convolutional networks (TCNs) on edge devices. Designed for near-sensor signal processing on energy-constrained platforms it features an optimized dataflow for one-dimensional convolution with a total power consumption in the low microwatt range. The parameterizable architecture combined with a hardware-aware neural architecture search (NAS) allows an automatic generation of domain-specific accelerator instances. Accurate models for power, performance, and area enable a fast design-space exploration. A UMA backend is provided to support network model deployment using TVM. |
AI/DSP-IP, AI/DSP-IP: Application-specific accelerators, AI/DSP-IP: Generation of accelerator instances, AI/DSP-IP: Parameterisable AI / DSP accelerators, AI/DSP-IP: Streaming-based platform integration, AI/DSP-IP: Training and compression for AI, AI/DSP-IP: Uniform deployment | Paul Palomero Bernardo |
| aiT and StackAnalyzer for RISC-V | aiT automatically computes safe bounds for the worst-case execution time of tasks in binary executables, taking into account the cache and pipeline behavior of the processor in question. StackAnalyzer automatically determines the worst-case stack usage of the tasks in embedded applications. It directly analyzes binary executables and considers all possible execution scenarios. The analyzers are based on the technique of static program analysis by abstract interpretation. Their results are valid for all inputs and each execution of a task. In Scale4Edge, the analyzers have been extended and adapted to the TGC architecture of MINRES so that they could successfully analyze the executables of the siren detection demonstrator. Installation packages for Linux and Windows are available from AbsInt (support@absint.com). |
Simple operations: Zcb, Smart Float, e.g. Bfloat16, ANT; IEEE 754, E = 16 (instead of 32) CPU Register, Exception - 1 Level (Machine Level only) - for Compiler: Assembler only, Exception - Basic, Counter, RV32I - Base Integer, 32-bit, X = ISA Extension (manuell), X: Multiply-Accumulate, X: Zero Overhead Loop, RV64I - Base Integer, 64-bit, A - Atomic Instructions, C - Compressed Instructions, D - Double-Precision Floating-Point, F - Single-Precision Floating-Point, M - Multiplication / Division, N - User-Level Interrupts, Q - Quad-Precision Floating-Point, V - Vector Operations, Zicsr - Control and Status Register (CSR), Zifencei - Instruction-Fetch Fence | AbsInt Angewandte Informatik GmbH |
| TGC-VP | Based on years of experience developing and integrating SystemC based virtual platforms in the industry, MINRES has created DBT-RISE (Dynamic Binary Translation Re-targetable Instruction Set Simulator), a versatile environment to rapidly implement ISS of any architecture. DBT-RISE serves as basis for the implementation of the TGC (The Good Core) ISS (TGC-VP). TGC-VP provides the following features:
|
Core Local Interrupt Controller, E = 16 (instead of 32) CPU Register, Exception, Exception - Basic, Exception - 1 Level (Machine Level only) - for Compiler: Assembler only, Exception - Basic, Counter, RISC-V for Low Power SoC, RV32I - Base Integer, 32-bit, X: Custom ISA Extensions, X = ISA Extension (automated), X: Multiply-Accumulate, X: Zero Overhead Loop, RV32E - Base Integer (embedded), 32-bit, C - Compressed Instructions, M - Multiplication / Division, N - User-Level Interrupts, Zicsr - Control and Status Register (CSR), Zifencei - Instruction-Fetch Fence, User (U-mode, lowest privileges), Machine (M-Mode, highest privileges) | MINRES |
| TGC Cores | The Good Folk Series is a highly flexible, scalable and configurable RISC-V based core family developed by MINRES. The standard cores can easily be tailored to specific application requirements using CoreDSL. It is technology independent, ensures integrity and targets low power edge computing applications. The comprehensive SDK and concise documentation makes it accessible to small and medium companies. The core family is developed with ASIL readiness criteria in mind, as an ISO 26262 certifiable out-of-context IP, where the pertinent functional safety documentation is available. There are five cores available: TGC5A - RV32E, 3 stages, 16 registers, for state machine controllers |
Core Local Interrupt Controller, Debug Support - Privileged Level 4, E = 16 (instead of 32) CPU Register, Exception, Exception - Basic, Exception - 1 Level (Machine Level only) - for Compiler: Assembler only, Exception - Basic, Counter, RISC-V for Low Power SoC, RV32I - Base Integer, 32-bit, X: Custom ISA Extensions, X = ISA Extension (automated), X: Multiply-Accumulate, X: Zero Overhead Loop, RV32E - Base Integer (embedded), 32-bit, C - Compressed Instructions, M - Multiplication / Division, N - User-Level Interrupts, Zicsr - Control and Status Register (CSR), Zifencei - Instruction-Fetch Fence, User (U-mode, lowest privileges), Machine (M-Mode, highest privileges) | MINRES |
| RISC-V VP | An extensible and configurable RISC-V based Virtual Prototype (VP) implemented in SystemC TLM. The feature set includes support for the RV32GC and RV64GC ISA, privilege levels (M,S,U), virtual memory, SW debug via Eclipse, a HiFive1 configuration and several operating systems including Linux. At UB the RISC-V VP serves as platform for several different research directions (visit https://agra.informatik.uni-bremen.de/projects/risc-v/ for further information and the most recent updates). |
Core Local Interrupt Controller, Internal Interrupt Controller, RV32I - Base Integer, 32-bit, RV32E - Base Integer (embedded), 32-bit, RV64I - Base Integer, 64-bit, A - Atomic Instructions, C - Compressed Instructions, D - Double-Precision Floating-Point, F - Single-Precision Floating-Point, G - Shorthand for IMAFD, M - Multiplication / Division, N - User-Level Interrupts, Zicsr - Control and Status Register (CSR), Zifencei - Instruction-Fetch Fence, User (U-mode, lowest privileges), Supervisor (S-Mode), Machine (M-Mode, highest privileges) | Universität Bremen |
| ETISS - Extendable Translating Instruction Set Simulator | ETISS is a C++ ISS (Instruction Set Simulator), which is designed to simulate instructions for a target core on a host computer. It translates binary instructions into C code and appends translated code into a block, which will be compiled and executed at runtime. As aforementioned, it is Extendable, thus it supports myriad level of customization by adopting the technique of plug-ins. ETISS supports varied Instruction Set Architectures (ISAs) according to user needs (see architecture models in |
AI/DSP-IP: CoreDSL 2.0, Code Size Reduction (like Zc) with ISAX macro instructions, Compressed Float Load: Zca, Zcf, Simple operations: Zcb, Exception, RV32I - Base Integer, 32-bit, X: Custom ISA Extensions, X = ISA Extension (automated), X = ISA Extension (manuell), X: Autoincrement Load+Store, X: Multiply-Accumulate, X: Zero Overhead Loop, RV32E - Base Integer (embedded), 32-bit, RV64I - Base Integer, 64-bit, A - Atomic Instructions, B - Bit Manipulation, C - Compressed Instructions, D - Double-Precision Floating-Point, F - Single-Precision Floating-Point, G - Shorthand for IMAFD, M - Multiplication / Division, V - Vector Operations, Zicsr - Control and Status Register (CSR), Zifencei - Instruction-Fetch Fence | Technische Universität München |
| CompCert - Formally verified C compiler | CompCert is a formally verified optimizing C compiler. It accepts most of the ISO-C 99 language, with some minor exceptions and a few useful extensions. Its intended use is the compilation of life-critical and mission-critical software written in C and meeting high levels of assurance. What sets CompCert apart from other production compilers is that it is formally verified, using machine-assisted mathematical proofs: the executable code it produces is proved to behave exactly as specified by the semantics of the source C program. Hence, all safety properties verified on the source code automatically hold as well for the generated executable. In the course of the Scale4Edge project, CompCert was given a backend for RISC-V, which had not been supported before, and CompCert for RISC-V has been combined with picolibc, a C library designed for embedded 32- and 64-bit microcontrollers with small memory. Installation packages for Linux and Windows are available for download from the AbsInt download server. |
Exception - 1 Level (Machine Level only) - for Compiler: Assembler only, Exception - Basic, Counter, RV32I - Base Integer, 32-bit, RV64I - Base Integer, 64-bit, A - Atomic Instructions, B - Bit Manipulation, C - Compressed Instructions, D - Double-Precision Floating-Point, F - Single-Precision Floating-Point, M - Multiplication / Division, N - User-Level Interrupts, Zicsr - Control and Status Register (CSR) | AbsInt Angewandte Informatik GmbH |